 Best Credit Cards
Best Credit Cards
 Credit Report
Credit Report
 Credit Report
Credit Report
 Insurance
Insurance
 IT Services
IT Services
 Car Insurance
Car Insurance
 Car Insurance
Car Insurance
 Credit Report
Credit Report
What are the 4 stages of big data processing? The 4 stages of big data processing: ingestion, storage, processing, and analysis. Learn how these stages work together to extract insights from large datasets.
Data acquisition: The first stage of big data processing is acquiring the data from various sources. These sources can include databases, social media platforms, sensors, websites, and more. The data can be structured (organized in a predefined format) or unstructured (not organized in a predefined format). The volume, velocity, and variety of the data determine the complexity of the data acquisition process.
Data storage: Once the data is acquired, it needs to be stored in a suitable infrastructure. This stage involves deciding on the storage architecture, such as data warehouses, data lakes, or cloud storage solutions. Data storage also involves organizing and cataloging the data for easy access and retrieval. Additionally, considerations regarding data security, backup, and replication are important aspects of data storage.
Data processing: After data acquisition and storage, the next stage is data processing. This stage involves transforming and analyzing the data to identify patterns, trends, and insights. Data processing can be performed using various techniques, including batch processing, real-time processing, and stream processing. Batch processing involves analyzing data in large volumes at regular intervals, while real-time processing focuses on analyzing data as it is generated. Stream processing is a hybrid approach that combines elements of both batch and real-time processing.
Data visualization: The final stage of big data processing is data visualization. Once the data has been processed and meaningful insights have been derived, it needs to be presented in a format that is easy to understand and interpret. Data visualization techniques, such as charts, graphs, and maps, are used to present the data visually. Effective data visualization enhances decision-making by enabling stakeholders to quickly grasp the key insights and trends within the data.
Overall, the four stages of big data processing - data acquisition, data storage, data processing, and data visualization - are crucial for extracting meaningful insights from large volumes of data. Each stage requires careful planning, specialized tools, and expertise to ensure the accurate and efficient processing of big data.
The 4 stages of big data processing are data acquisition, data storage, data processing, and data analysis.
What is data acquisition in big data processing?Data acquisition in big data processing refers to the process of collecting large volumes of data from various sources such as sensors, social media, websites, and IoT devices.
What is data storage in big data processing?Data storage in big data processing involves storing the collected data in a distributed system such as Hadoop Distributed File System (HDFS) or a cloud-based storage solution like Amazon S3.
What is data processing in big data processing?Data processing in big data processing involves transforming and organizing the collected data into a format that is suitable for analysis. This can include tasks such as cleaning, filtering, aggregating, and integrating the data.
What is data analysis in big data processing?Data analysis in big data processing involves analyzing the processed data to extract meaningful insights, patterns, and trends. This can be done using various techniques such as statistical analysis, machine learning, and data visualization.
 LATEST ARTICLES
LATEST ARTICLES

Do rental cars come with liability insurance Texas?

Do you get cheaper insurance if you call?
Do most people in Florida have flood insurance?

Is it better to own an Allstate or State Farm?

Is it better to have 80% or 100% coinsurance?

Is home insurance the same as property insurance?
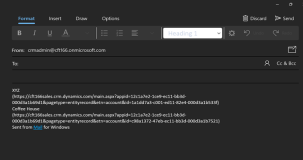
How do I link an email to dynamics?

Is Medicare more expensive than Obamacare?

Is HSA or FSA use it or lose it?
Does credit one bank report to Equifax?
Does disputing a collection restart the clock?
Does closing a secured credit card hurt your score?
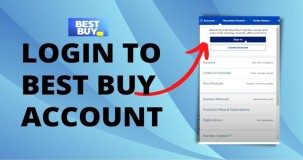
How do I pay my Best Buy account?

How do I lower my APR rate?

How do I make a balance transfer offer?

What are the challenges of being an insurance agent?
What are the pros and cons of paying off a loan quicker?
What are the 5 key challenges facing the insurance industry?
 POPULAR ARTICLES
POPULAR ARTICLES
Do rental cars come with liability insurance Texas?
Do you get cheaper insurance if you call?
Do most people in Florida have flood insurance?
Is it better to own an Allstate or State Farm?
Is it better to have 80% or 100% coinsurance?
Is home insurance the same as property insurance?
How do I link an email to dynamics?
Is Medicare more expensive than Obamacare?
Is HSA or FSA use it or lose it?
Does credit one bank report to Equifax?
 Facebook
Facebook  Twitter
Twitter  Whatsapp
Whatsapp  Tumbler
Tumbler  Pinterest
Pinterest