 Best Credit Cards
Best Credit Cards
 Credit Report
Credit Report
 Credit Report
Credit Report
 Insurance
Insurance
 IT Services
IT Services
 Car Insurance
Car Insurance
 Car Insurance
Car Insurance
 Credit Report
Credit Report
What are the four 4 main data mining techniques? The four main data mining techniques include classification, clustering, regression, and association rule mining. Explore how these techniques provide valuable insights from large datasets.
1. Classification:
Classification is a data mining technique that involves categorizing data into predefined classes or groups. It is useful for predicting categorical variables based on input features. The goal of classification is to build a model that can accurately assign new, unseen instances to the correct class. Classification algorithms, such as decision trees, neural networks, and support vector machines, are commonly used in this technique. Classification has various applications, such as spam email detection, customer segmentation, and disease diagnosis.
2. Clustering:
Clustering is a data mining technique used to group similar data objects together. It aims to identify inherent patterns or structures in the data without any predefined classes. The goal is to divide the data into clusters, where objects in the same cluster are more similar to each other than those in different clusters. Clustering helps in discovering hidden patterns, identifying outliers, and understanding the overall structure of the data. Popular clustering algorithms include k-means, hierarchical clustering, and DBSCAN.
3. Association Rule Mining:
Association rule mining is a data mining technique used to discover interesting relationships or associations in large datasets. It involves finding frequent itemsets, which are sets of items that frequently occur together. Association rules indicate the likelihood of co-occurrence between different items. These rules are typically represented in the form of "if X, then Y." Association rule mining has various applications, such as market basket analysis, product recommendations, and web usage mining. The Apriori algorithm is commonly used for association rule mining.
4. Regression:
Regression is a data mining technique used to predict continuous numerical variables based on input features. It aims to establish a functional relationship between the input variables and the output variable. Regression models allow us to estimate the value of the dependent variable based on the values of independent variables. This technique is widely used in various domains, such as finance, economics, and healthcare. Linear regression, logistic regression, and polynomial regression are some common regression techniques.
Data mining techniques play a crucial role in today's data-driven world. Organizations generate and accumulate vast amounts of data from various sources, such as social media, sensors, and transactional databases. Applying data mining techniques helps organizations make sense of this data, extract useful insights, and make informed decisions. These techniques enable businesses to uncover hidden patterns, identify trends, understand customer behavior, and improve overall performance.
In conclusion, the four main data mining techniques are classification, clustering, association rule mining, and regression. Each technique serves a specific purpose in discovering patterns, relationships, and trends in large datasets. Applying these techniques empowers organizations to gain valuable insights, improve decision-making, and stay ahead in today's competitive landscape. In this data-driven era, leveraging data mining techniques is crucial for organizations to unlock the full potential of their data and drive success.
The four main data mining techniques are classification, clustering, regression, and association.
2. What is classification in data mining?Classification is a data mining technique that involves organizing data into predefined categories or classes based on their attributes. It is used to predict the class or category of an object or instance based on its characteristics.
3. How does clustering work in data mining?Clustering is a data mining technique that groups similar objects together based on their characteristics or attributes. It aims to find patterns or relationships among the data and discover natural groupings or clusters within the dataset.
4. What is regression in data mining?Regression is a data mining technique that analyzes the relationship between a dependent variable and one or more independent variables. It is used to predict or estimate the value of the dependent variable based on the values of the independent variables.
5. What is association in data mining?Association is a data mining technique that discovers relationships or associations between items in a dataset. It is commonly used in market basket analysis to identify patterns and correlations between different products that are frequently purchased together.
 LATEST ARTICLES
LATEST ARTICLES

Do rental cars come with liability insurance Texas?

Do you get cheaper insurance if you call?
Do most people in Florida have flood insurance?

Is it better to own an Allstate or State Farm?

Is it better to have 80% or 100% coinsurance?

Is home insurance the same as property insurance?
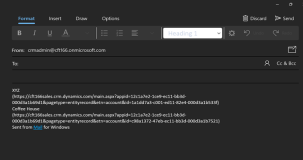
How do I link an email to dynamics?

Is Medicare more expensive than Obamacare?

Is HSA or FSA use it or lose it?
Does credit one bank report to Equifax?
Does disputing a collection restart the clock?
Does closing a secured credit card hurt your score?
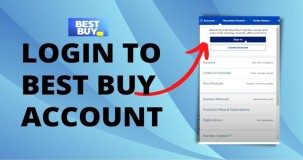
How do I pay my Best Buy account?

How do I lower my APR rate?

How do I make a balance transfer offer?

What are the challenges of being an insurance agent?
What are the pros and cons of paying off a loan quicker?
What are the 5 key challenges facing the insurance industry?
 POPULAR ARTICLES
POPULAR ARTICLES
Do rental cars come with liability insurance Texas?
Do you get cheaper insurance if you call?
Do most people in Florida have flood insurance?
Is it better to own an Allstate or State Farm?
Is it better to have 80% or 100% coinsurance?
Is home insurance the same as property insurance?
How do I link an email to dynamics?
Is Medicare more expensive than Obamacare?
Is HSA or FSA use it or lose it?
Does credit one bank report to Equifax?
 Facebook
Facebook  Twitter
Twitter  Whatsapp
Whatsapp  Tumbler
Tumbler  Pinterest
Pinterest